Week 13: Data visualization
| Markdown script for this week | Datasets to use in the script |
|---|---|
| Markdown script | Whole ETtoday corpus (after cleaning) |
| KWIC analysis of you ‘to have’ | |
| Most frequently used words |
1 Creating figures of the results, why?
1.1 Some reflexions on the visual presentation of the results
A great question to ask is: Why adding figures after all? We scraped the data from the Internet, we cleaned them and we analyzed them based on our research question. We even have tables to present as well, and all we need to do now is to interpret the results to deliver a great story. So, what is the place for figures?
Think about it
When you are reading a website, or a journal article, or even when you are scrolling through social medias, do you usually read long yet very complete and informative texts first, or are you more attracted to headlines and pictures, before turning to the text?
If you are aware of this natural human behavior, then you have surely already understood why adding figures to text and table results is helpful. It is because the human visual system is so important that stimulating it will be a plus when communicating the results.
Knowing how to present the results in a figure is very important as well. Having a great figure able to summarize the results such that we can grasp the intended message of the study at one glance will determine the success of the whole presentation. Conversely, a messy figure, containing too much information or just presented in an inappropriate way will blur the message, affecting the success of the presentation. Adding a figure is not enough, it requires some strategic thinking as well! You can have a look at the figures plotted with R on this webpage. Some are quite straightforward, while some are clearly just messy.
1.2 Examples of some types of figures
1.2.1 Introduction to the figures we will learn in the tutorial: word clouds, and frequency dot plots
For this class, we will present two types of figures which are commonly used to present results from corpus exploration. The first one is called “word cloud”. It is named this way, because it looks like a cloud which is made out of words. The size of these words reflect their relative frequency in the corpus analyzed. In other words, the bigger the word, the higher its frequency in the corpus. It is a way to present frequency results in a very intuitive way!
A quick search on Google shows that you can create them easily with dedicated websites. I personally used them before, and it can be quite fun to play with them. I invite you to do so, you will have a better grasp of what a word cloud is!
Frequency dot plots are another way to present the same kind of results. It looks less funny than word clouds, but it exhibits the advantage that you can add more information if you want. Put differently, where word clouds are great for their visual impact thanks to their relatively minimalist design, frequency dot plots are very useful when you want to display different types of information at the same time!
I invite you to watch this YouTube video if you want to know more about frequency dot plots (please click on the image below).
1.2.2 Lexical dispersion plot: Compare the use of keywords across texts and/or time
So far, we looked at the frequency of words within single documents and within the same time frame. Maybe you will be interested in other types of analyses:
Comparing the frequency of use of two keywords within one document;
Comparing the frequency of use of the same keyword or different keywords across time and/or between documents.
One way to visualize the results of such an analysis is to use a “lexical dispersion plot”. There is a full tutorial on the quanteda website, including the R codes and the example below. Here is the link to the website: Quanteda tutorial for figures.
Let’s look at an example. Let’s say that you are interested in two words, “American” and “people”, and how they are used in inaugural speeches of US presidents, especially (a) their frequency, and (b) the moments when they are used in the speech. You will obtain a figure like this:
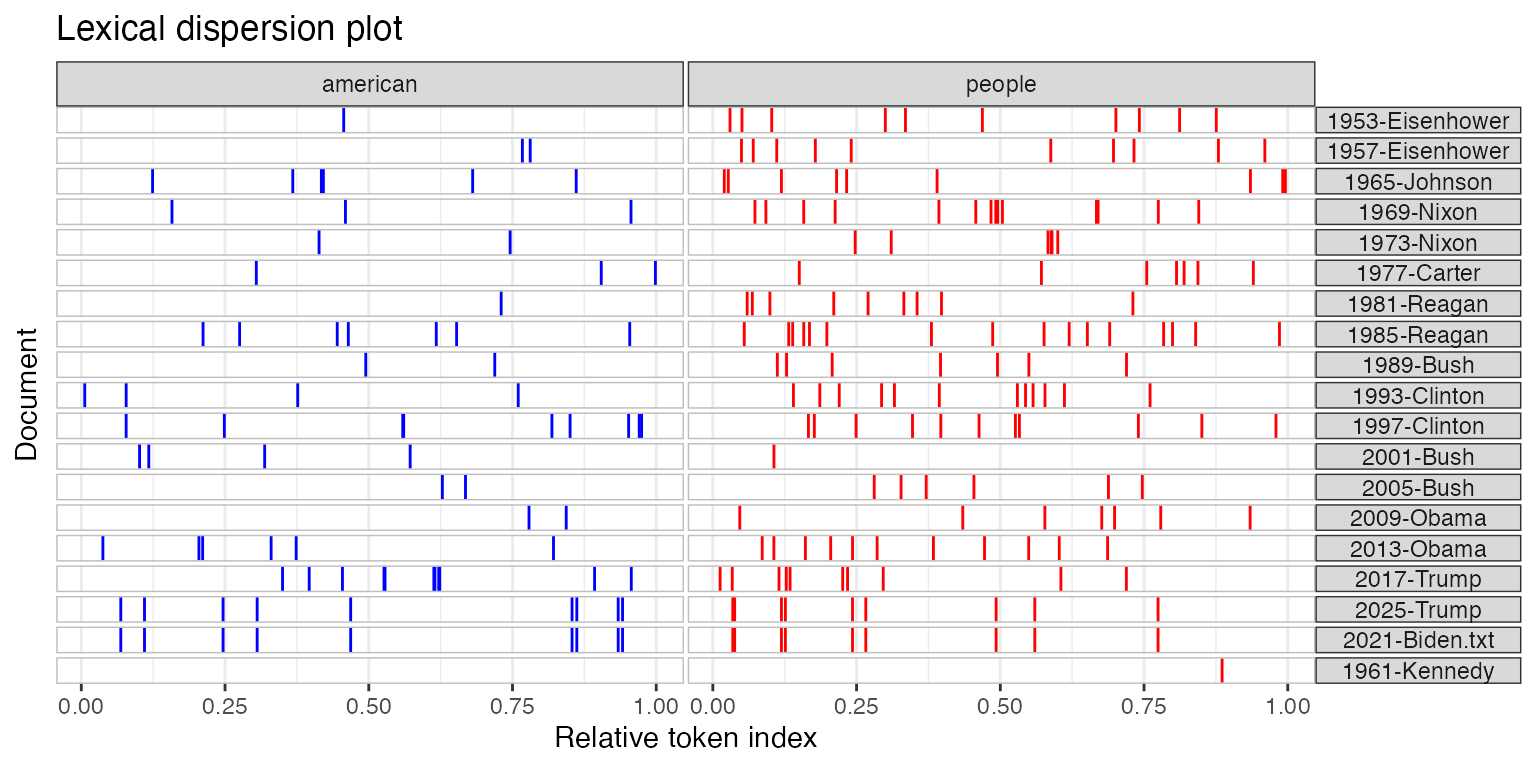
Again, this is only a figure. Once we have it, you may have this question in mind: and so what? And this is the perfect question to ask. Our role, once we have the results and plotted the data, is to make them meaningful. Generally, we interpret the results according to the research question, such that we can answer the “and so what?” question.
2 Let’s do the work with R
2.1 Two packages: ‘quanteda’ and ‘ggplot2’
In this tutorial, I will only explain how to plot two types of figures: Word clouds and frequency dot plots. There are two reasons for that. The way we analyzed the data from ETtoday last week may not be ideal for a lexical dispersion plot. Of course, we could use the data from ETtoday, and reanalyze then to include, for example, different types of texts (‘politics’ vs. ‘society’ articles), or focusing on differences over time. The second reason is that the tutorial on the quanteda website is very clear, so you can really just look at it to understand how it works. In this tutorial for this week, we will mainly use two packages to plot the data.
2.1.1 ‘quanteda’, or more precisely, ‘quanteda.textplots’
Again, such as last week, we will use the ‘quanteda’ library, and its sub-library, ‘quanteda.textplots’. If not already done, you will need to install them (if you forgot how to do so, you can go back to Week 5). And then you will just need to load them.
2.1.2 ‘ggplot2’
Another package we are going to use is called ‘ggplot2’.
![]()
The ggplot2 package is very powerful and useful to create figures. You can go to their website and scroll through examples of what is possible to do. Once you are very familiar with ggplot figures, you will be amazed when you are reading the news online by the fact that many figures look so familiar. This package is therefore one of the best ways to obtain very professional, good-looking figures that will help you not only for this tutorial, but also for any kind of study (Master thesis/PhD dissertation, case studies to conduct in your job, etc.).
You can refer to the ggplot2 website here. There are cheatsheets as well, to have an idea of all the functions at a glance:


2.2 Workflow for word clouds and frequency dot plots
Like always, here is the workflow for the R tutorial this week:
2.3 Explanation of the R code
2.3.1 Prepare the environment
2.3.1.1 Load the libraries
We load the necessary tools. This week, we introduce quanteda.textplots for word clouds and ggplot2 for professional charts.
Crucial for Chinese Text: Note the showtext library. By default, R plots often fail to render Chinese characters (showing empty boxes instead). showtext_auto() tells R to automatically detect and use a font that supports Chinese characters.
library(quanteda)
library(quanteda.textstats)
library(quanteda.textplots)
library(stringr)
library(ggplot2)
library(showtext)
library(scales)
#Sys.setlocale(category = "LC_ALL", locale = "cht")
# Use showtext_auto() to enable automatic font discovery and display Chinese characters
showtext_auto()2.3.1.2 Load the files used for the analyses
We load the data processed in previous weeks (the cleaned corpus and the KWIC analysis of “有”).
load(file = "ArticleETToday_CorpusCourse_CLEAN.Rdata")
load(file = "ArticleETToday_KWIC_You.Rdata")
load(file = "ArticleETToday_Top100words.Rdata")2.3.2 Visualizing KWIC
2.3.2.1 Visualizing overall frequency in the “post” context
We want to visualize the words that appear after our keyword (“有”).
2.3.2.1.1 Word cloud
To create a word cloud, we first convert the text tokens into a Document-Feature Matrix (DFM) using dfm(). This counts every word.
However, raw text data is noisy. We use dfm_trim() to filter the words. This function works by setting “thresholds” for which words to keep:
min_termfreq(The Floor): This removes rare words. Code:min_termfreq = 100. Logic: If a word appears fewer than 100 times, it’s likely a typo, a name, or irrelevant noise. We cut it out to clean the data.max_termfreq(The Ceiling): This removes extremely common words. Code:max_termfreq = 10000. Logic: In Chinese, functional particles like “的” (de) appear thousands of times. They are so big in a word cloud that they hide the meaningful content words. By setting a maximum limit, we exclude these “super-words” so we can see the actual topics.
The code below generates two clouds: one with the super-frequent words (to show the “raw” reality) and one without them (to show the meaningful content).
## We need to tranform the tokenized data into a 'dfm' dataset
kwic_post_freq <- dfm(
tokens(kwic_data$post,
remove_punct = TRUE,
remove_numbers = TRUE,
remove_separators = TRUE))
# Version 1: Keep high-frequency words (Only trims rare words < 100)
kwic_post_freq_trim_WithDE <- dfm_trim(kwic_post_freq,
min_termfreq = 100,
verbose = TRUE)dfm_trim() changed from 21,355 features (65,657 documents) to 540 features (65,657 documents)# Version 2: Remove high-frequency words (Trims words > 10,000)
# This removes "stopwords" like '的' without needing a specific list.
kwic_post_freq_trim_WithoutDE <- dfm_trim(kwic_post_freq,
min_termfreq = 100,
max_termfreq = 10000,
verbose = TRUE)dfm_trim() changed from 21,355 features (65,657 documents) to 539 features (65,657 documents)textplot_wordcloud(kwic_post_freq_trim_WithDE,
max_words = 100,
min_size = 1,
max_size = 5,
rotation = FALSE,
random_order = FALSE,
color = c('red', 'green', 'blue', "orange"))
textplot_wordcloud(kwic_post_freq_trim_WithoutDE,
max_words = 100,
min_size = 1,
max_size = 5,
rotation = FALSE,
random_order = FALSE,
color = c('red', 'green', 'blue', "orange"))
2.3.2.1.2 Frequency plots
Word clouds are pretty, but Dot Plots (created with ggplot2) are more accurate for analysis.
reorder(feature, frequency): This is the most important part of this code. Without it, the graph would list words alphabetically (Apple, Banana, Carrot). This function forces the graph to list words by size (Carrot, Apple, Banana), making it a readable ranking.scale_x_continuous: This adds commas to the numbers on the axis (e.g., “1,000” instead of “1000”) using the scales library.
## We need to tranform the tokenized data into a 'dfm' dataset
kwic_data_freq_PostContext <- dfm(
tokens(kwic_data$post,
remove_punct = TRUE,
remove_numbers = TRUE,
remove_symbols = TRUE)
)
kwic_data_freq_PostContext <- textstat_frequency(kwic_data_freq_PostContext)
## Now plots
# Plot 1: Top 100 words
ggplot(head(kwic_data_freq_PostContext, 100),
aes(x = frequency,
y = reorder(feature, frequency))) +
geom_point() +
labs(x = "Frequency", y = "Word") +
scale_x_continuous(labels = label_comma())
# Plot 2: Top 30 words (Easier to read in a report)
ggplot(head(kwic_data_freq_PostContext, 30),
aes(x = frequency,
y = reorder(feature, frequency))) +
geom_point() +
labs(x = "Frequency", y = "Word") +
scale_x_continuous(labels = label_comma())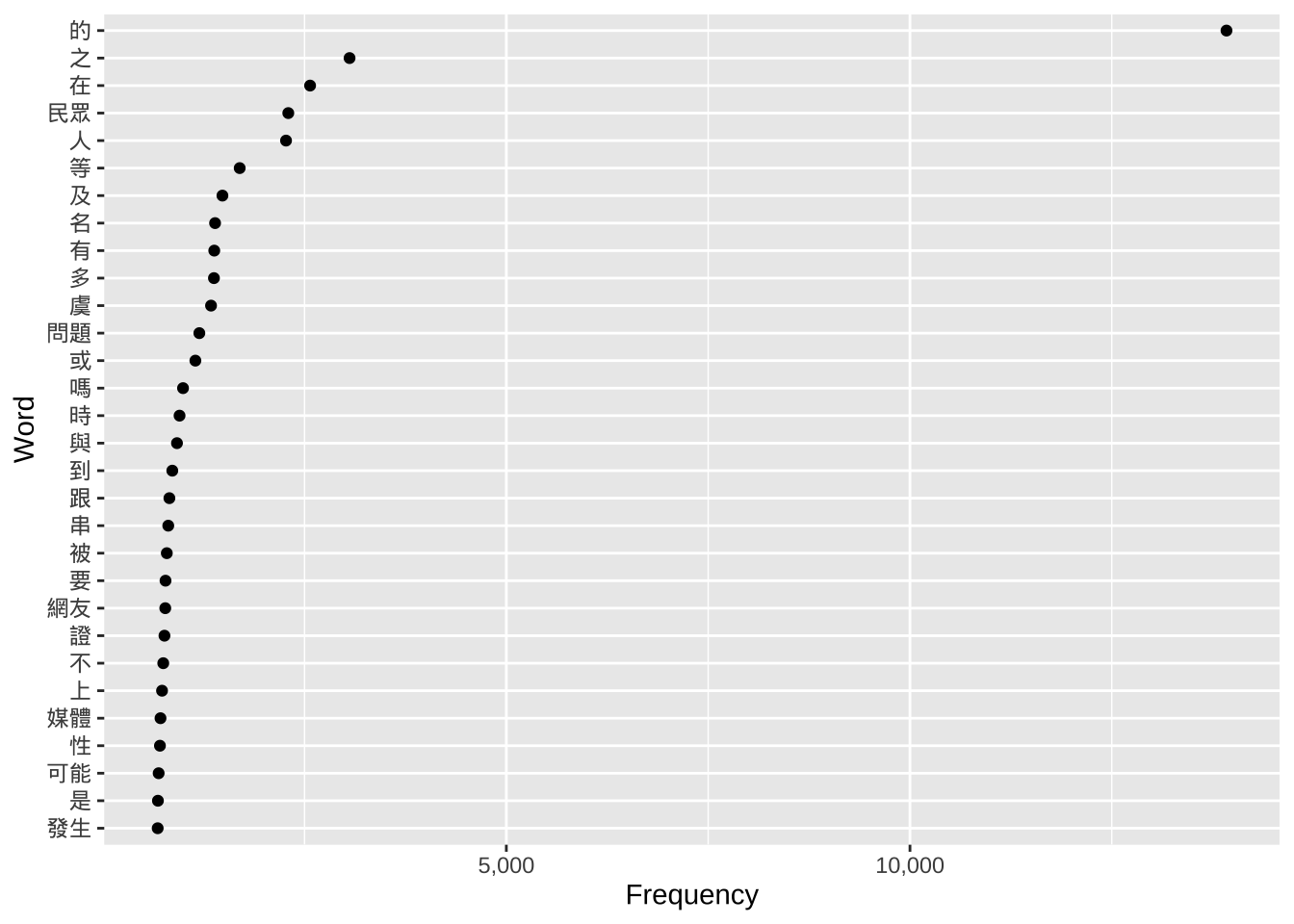
2.3.2.2 Visualizing frequency of the first word following the keyword
Sometimes the context (window) is large. Here, we zoom in on only the very first word after “有”.
2.3.2.2.1 Word clouds
We use word(kwic_data$post, 1) from the stringr package. This function grabs the 1st word from the text string. We then repeat the DFM and Word Cloud process.
## Extract the first word
kwic_data$post_first_word <- word(kwic_data$post, 1)
## We need to tranform the tokenized data into a 'dfm' dataset
kwic_post_FirstWord_freq <- dfm(
tokens(kwic_data$post_first_word,
remove_punct = TRUE,
remove_numbers = TRUE,
remove_separators = TRUE))
kwic_postFirstWord_freq_trim <- dfm_trim(kwic_post_FirstWord_freq,
verbose = TRUE)dfm_trim() changed from 7,690 features (65,657 documents) to 7,690 features (65,657 documents)textplot_wordcloud(kwic_postFirstWord_freq_trim,
max_words = 100,
min_size = 1,
max_size = 5,
rotation = FALSE,
random_order = FALSE,
color = c('red', 'green', 'blue', "orange", "cyan"))
2.3.2.2.2 Frequency plots
We repeat the ggplot dot plot for the “First Word” dataset. This allows us to see the most common direct objects or verbs following “有”.
## Extract the first word
kwic_data$post_first_word <- word(kwic_data$post, 1)
## We need to tranform the tokenized data into a 'dfm' dataset
kwic_data_freq_PostFirstWord <- dfm(
tokens(kwic_data$post_first_word,
remove_punct = TRUE,
remove_numbers = TRUE,
remove_symbols = TRUE)
)
kwic_data_freq_PostFirstWord <- textstat_frequency(kwic_data_freq_PostFirstWord)
## Now plots
# Plot 1
ggplot(kwic_data_freq_PostFirstWord,
aes(x = frequency,
y = reorder(feature, frequency))) +
geom_point() +
labs(x = "Frequency", y = "Word") +
scale_x_continuous(labels = label_comma())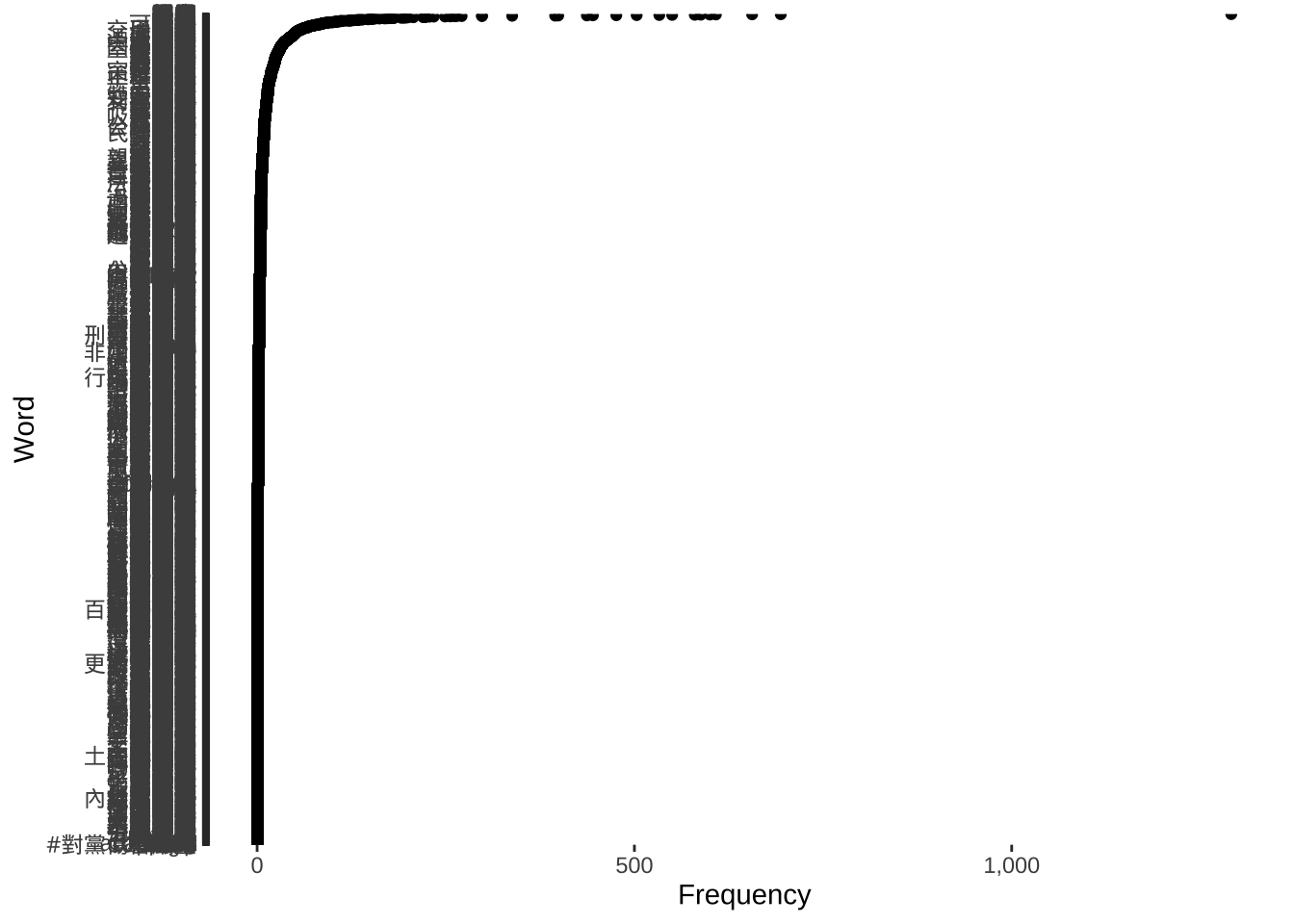
# Plot 2
ggplot(head(kwic_data_freq_PostFirstWord, 30),
aes(x = frequency,
y = reorder(feature, frequency))) +
geom_point() +
labs(x = "Frequency", y = "Word") +
scale_x_continuous(labels = label_comma())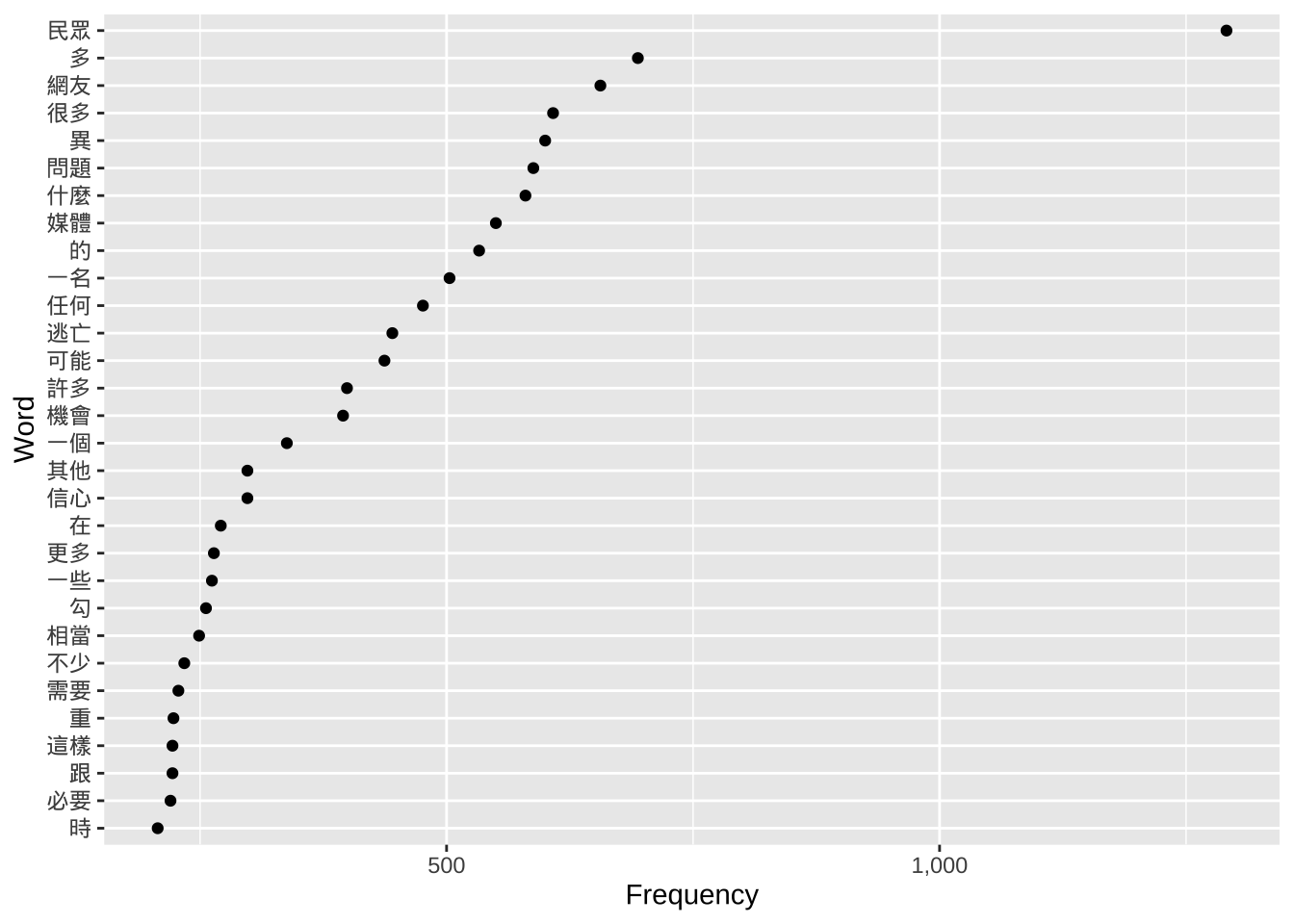
2.3.3 Frequency tables
2.3.3.1 Use word clouds
Finally, we apply these techniques to the entire corpus (Article_total2$body), not just the search results.
Because the whole corpus is huge, the frequency numbers are much higher. Notice how we adjusted the dfm_trim settings:
min_termfreq = 10000: We only keep words that appear at least 10,000 times.max_termfreq = 300000: We remove words that appear more than 300,000 times. In this specific dataset, that top layer is almost certainly just the character “的”. By removing it, the word cloud reveals the actual news topics.
## We need to tranform the tokenized data into a 'dfm' dataset
Article_tokens_frequency <- dfm(
tokens(Article_total2$body,
remove_punct = TRUE,
remove_numbers = TRUE,
remove_separators = TRUE))
Article_tokens_frequency_trim_WithDE <- dfm_trim(Article_tokens_frequency,
min_termfreq = 10000,
verbose = TRUE)dfm_trim() changed from 69,862 features (247,374 documents) to 205 features (247,374 documents)Article_tokens_frequency_trim_WithoutDE <- dfm_trim(Article_tokens_frequency,
min_termfreq = 10000,
max_termfreq = 300000,
verbose = TRUE)dfm_trim() changed from 69,862 features (247,374 documents) to 204 features (247,374 documents)textplot_wordcloud(Article_tokens_frequency_trim_WithDE,
max_words = 100,
min_size = 1,
max_size = 5,
rotation = FALSE,
random_order = FALSE,
color = c('red', 'green', 'blue', "orange"))
textplot_wordcloud(Article_tokens_frequency_trim_WithoutDE,
max_words = 100,
min_size = 1,
max_size = 5,
rotation = FALSE,
random_order = FALSE,
color = c('red', 'green', 'blue', "orange"))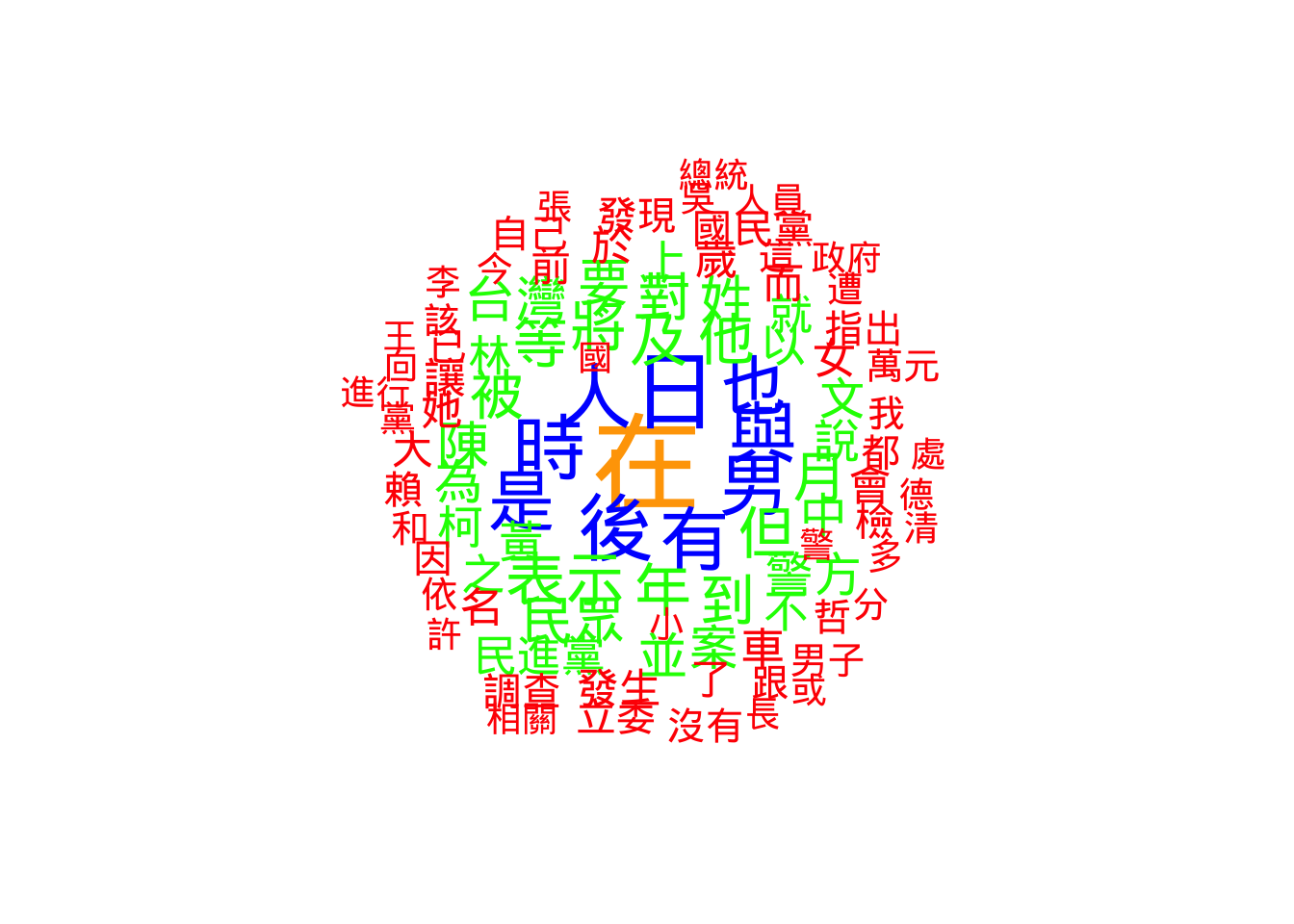
2.3.3.2 Frequency plots with ggplot
We use ggplot one last time on the table_FreqWord_Top100 dataset created in Week 12.
Plot 1 shows all top 100 words. This can look crowded.
Plot 2 uses head(..., 30) to show only the top 30. This is a standard practice in data visualization: reducing the amount of data shown to make the chart more readable for an audience.
## We can directly use the dataset we created last week
# Plot 1
ggplot(table_FreqWord_Top100,
aes(x = frequency,
y = reorder(feature, frequency))) +
geom_point() +
labs(x = "Frequency", y = "Word") +
scale_x_continuous(labels = label_comma())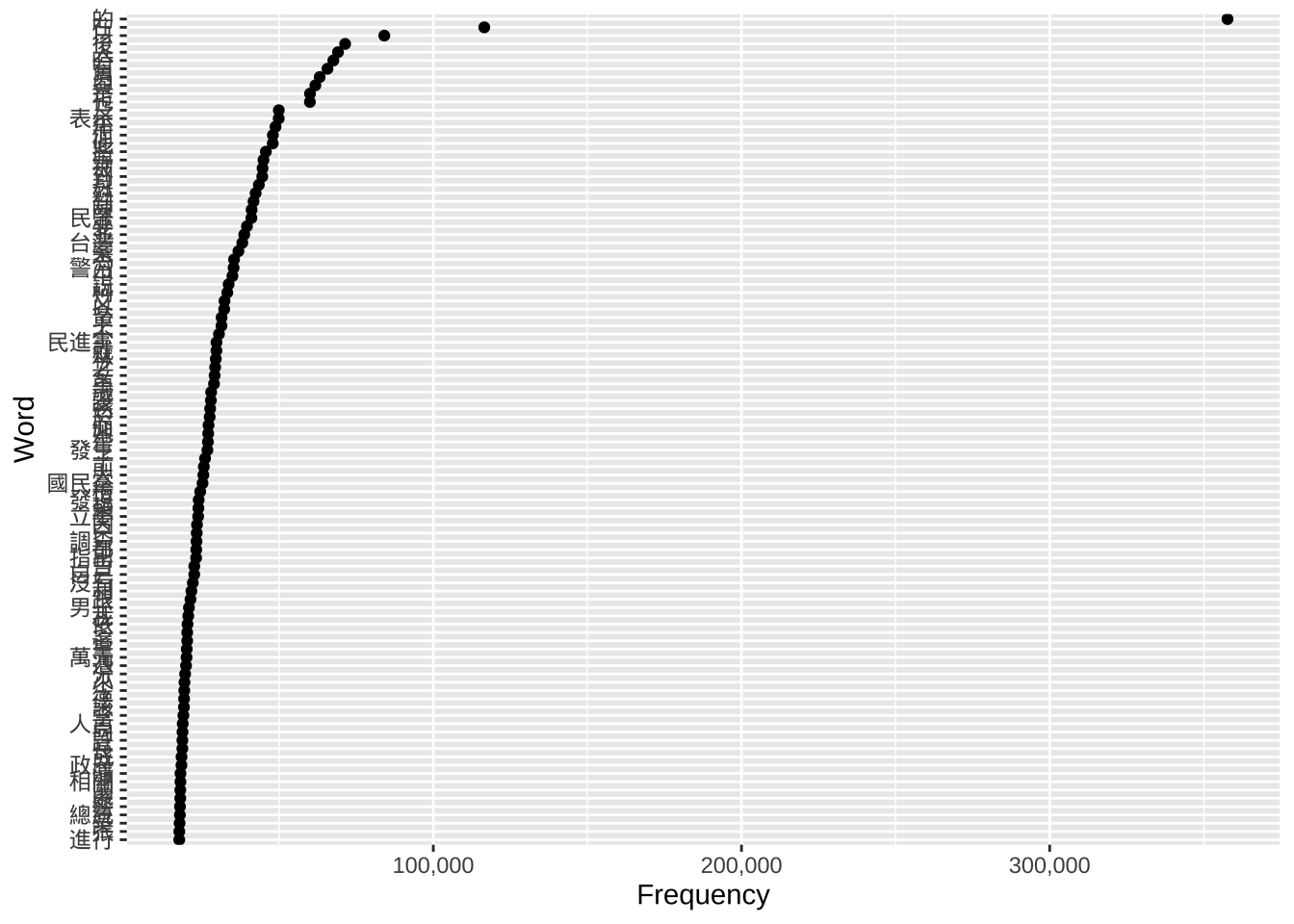
# Plot 2; Observe attentively: What's the difference with the plot above?
ggplot(head(table_FreqWord_Top100, 30),
aes(x = frequency,
y = reorder(feature, frequency))) +
geom_point() +
labs(x = "Frequency", y = "Word") +
scale_x_continuous(labels = label_comma())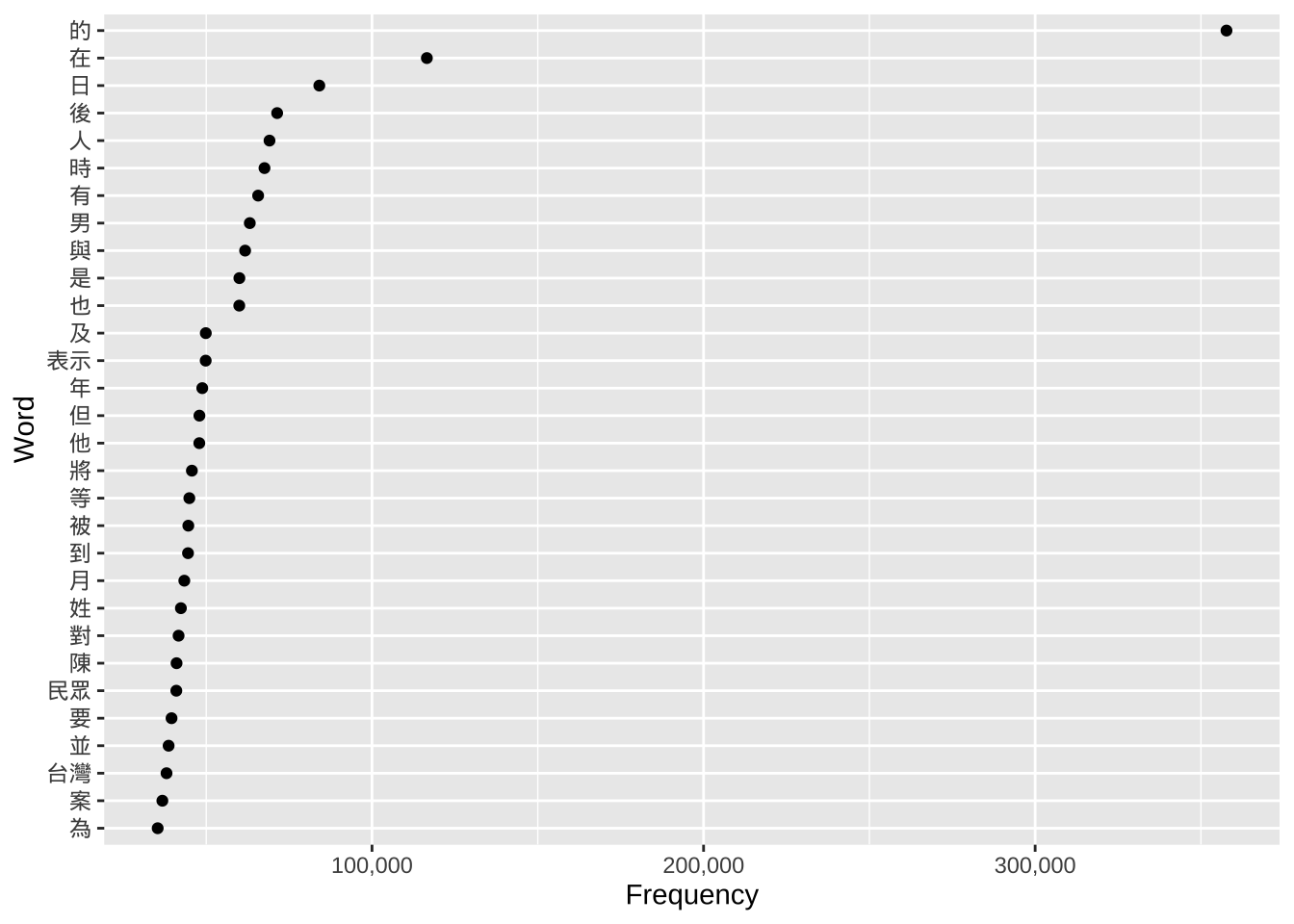
3 Markdown document and PDF output file
You can find the pre-filled Markdown document of this section here. Here is the PDF output of the same document.