Introduction
Slides of this section
1 Structure and workflow of the tutorial
The workflow of a typical corpus-based study is generally as in the image below.
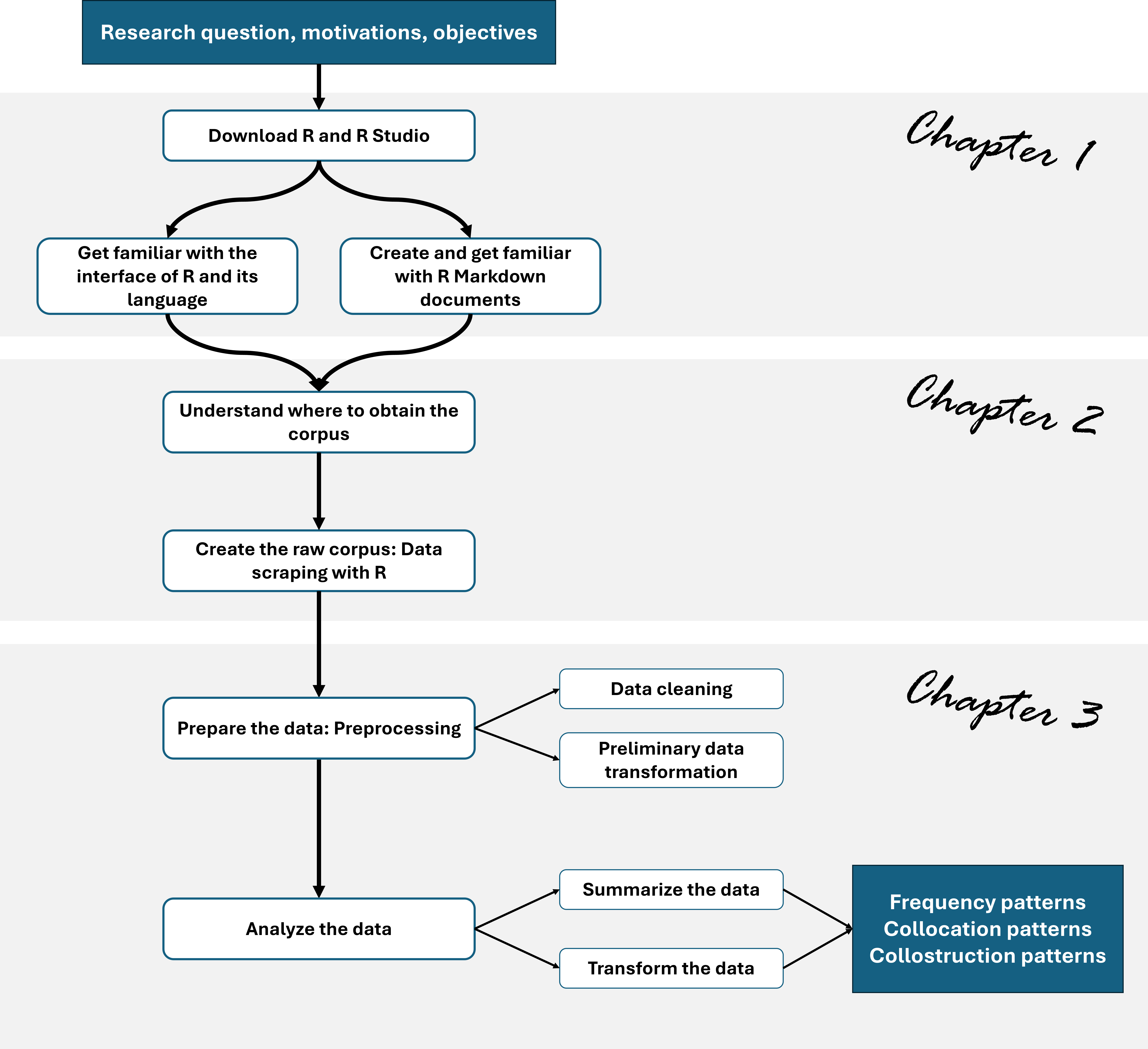
The sections and their links can be found in the Table of Contents on the left in addition to the table below.
| Chapter and content | Link |
|---|---|
| Chapter 1: Getting started | |
| Download and install R/RStudio | link |
| Presentation of R/RStudio | link |
| Working with markdown files | link |
| Chapter 2: Let’s get our data | |
| Understanding where the data are on the Internet | link |
| Scraping the data from the web with R | link |
| Chapter 3: Cleaning and analyzing the data | |
| Preprocess the data: Cleaning and transformations | link |
| Analyzing the data | link |
The picture and table above show what this tutorial will cover. In other words, this tutorial will not discuss the fundamental concepts of corpus linguistics, how to ask a research question and how to motivate it. If you are interested in it, you can read the book published by Anatol Stefanowitsch in 2020, available for free here. This tutorial will also not discuss advanced statistical methods in corpus linguistics, such as classification analyses or vector space representations.
2 How to get through the exercises
The best (if not only) way to learn how to use programming language is just with practice. There are two ways to do so throughout the tutorial. In either case, I highly recommend to use markdown scripts (to know more about markdown scripts, you can refer to Section 1.3.
- I will provide at the beginning of each section a markdown file prefilled with the structure of the section. You can download this file and open it with R, and just paste the codes at the relevant sections of the script.
- Alternatively, you may wish to write the script yourself, and to work based on the codes in each section. This is also a great way to learn how to structure a markdown file alone!